The Clinical Trials Assistant is a multi-agent generative AI application whose goal is to help users find completed, published results of clinical trials for treatment or prevention of a disease that the user is interested in. Large Language Models (LLMs) are used in validating user input, summarizing complex text for people without a medical background, and evaluating the summarizations.
This is my capstone project for the Google Kaggle 5-day Generative AI Course. The application demonstrates a few uses of LLMs in a pipeline to produce easy to understand summarizations of the trial results. My Kaggle application is here.
The agents that were created to validate input data and summarize text are talking to LLMs hosted by Google.
This blog (1) introduces LLMs, (2) highlights some of the application's lifecycle, and (3) presents highlights from the application. References used in the blog are at the bottom of the article.
skip to lifecycleskip to the application
(1) LLMs
LLMs are able to accomplish complex goals through abilities built upon the ability to predict the next word in a sequence of words. Predicting the next word is a difficult task. The space of possible events for all combinations of words is far larger than the amount of data that could be given to a model, also, the model itself has far fewer parameters than that space for all possible events, so the problem of learning the probabilities of word combinations is severely under-determined.Note that in these algorithms "word" might be partial words or even byte-pairs.
To predict the combination of words, we define the joint and for some tasks, the marginal probabilities of the words. Let , then, by the chain rule of factorization, we have the joint probability . Predicting the last word given the words preceding it, that is, has a complexity of ) and so that calculation is not tractable. To make the problem tractable while still preserving the autoregressive property of using the previous steps to predict the current step, many different algorithms have been made. The transformer and uses of transformers in LLMs are the latest of these algorithms.
LLMs learn the probabilities of sequences of words by training on a very large corpus of words to predict the next word. They're built from transformers which are generative models that include autoregressive properties with non-linear weights. The transformer was created by Google in 2017. Their network architecture was less complex than the state-of-the-art (SOTA) RNN and CNN models, was parallelizable, required less training time, and demonstrated higher quality results on language translations.
Milestones in LLM components
| Year | Constructs | |
|---|---|---|
| 2015 | Attention | |
| 2017 | Transformer Architecture | |
| 2018 | Contextual Word Embeddings and Pretraining | |
| 2019 | Prompting |
[view/hide]
Details of Transformers and their components.
Briefly, definitions of a few more constructs in order to understand the Transformer architecture are introduced.
Vector embeddings
are ways to represent data in a compact, binned (grouped) manner. For instance, if a language had a million words, a vector would be 1 million elements in length if each word was an element. The length of a vector is also the number of indices on the vector. Words can be grouped by meanings or some unknown aspects to make far fewer than a million indices. For example instead of a vector of [dog, cat, fence, sidewalk] with 4 indices, one could make a vector of [[dog or cat], fence, sidewalk] with 3 indices. The vector elements are placeholders for existence of that object. Text grouped into such a "compressed" vector are the embeddings. Efficient embeddings may have latent (hidden) groupings that are not easy to interpret, and they may share the same embedded vector space with objects of different types (types being modalities, e.g. image, text, audio, or measurements that have embeddings that share the same vector embedding space). There are- embeddings that represent meaning, and
- encodings that are like embeddings that represent position within their context such as the position or words in a sentence or relative to another word.
Distances
as differences between a model output representation and a representation of ground truth or replacement for it are part of what is needed to calculate model objectives efficiently. The model, in the training stage, is an optimization problem and the objective is a function to minimize. Objectives with losses such as cross-entropy, K-L divergence or Jenson-Shannon divergence, use of contrastive learning, etc. can be used.Sequence
is an ordered set of elements.Encoder-Decoder Architecture
The encoder maps the input representation sequence to a latent sequence which are continuous representations. The sequence z are inputs to the decoder which generates ouptut symbols one at a time.Feed Forward Network
is a network composed of a series of one or more layers that accept input and output a result. A layer multiplies the input by a weight matrix, adds a bias vector and then can put that resulting matrix through an activation function resulting in the output for that layer. The activation function makes non-linearity possible to express. The output of one layer is an input for the next layer.Position-wise Feed Forward Network
is a Feed Forward Network with 2 layers. For each position in the sequence separately and identically, the network layers are defined asAttention
determines the importance of each component in a sequence relative to the other components in another sequence or that same sequence (self-attention). In context of a transformer, the components of the sequence are tokens.- Attention allows a sequence element access to other sequence elements that are not necessarily its predecessor in terms of order.
- The attention score allows a model to focus on an important relationship.
- The goal of attention is to calculate a "context vector" that is the weighted sum of all input element attention scores w.r.t. a current task.
Scaled Dot Product Attention
is a form of Self-Attention mechanism. An attention score is calculated from a query vector q, key vector k, and value vector v.- The query and key vectors have dimension The value vectors have dimension
- For a given q,
- In matrix form,
Multi-Head Attention
is an extension of Self-Attention mechanism. The "heads" refers to multiple, independent attention calculations that are performed in parallel. The input is partitioned into several parts, each processed thru a different attention head.- Each head has its own set of learnable linear projections (weights) for the query (Q), key (K), and value (V) vectors.
- For each head (partition), the Scaled Dot Product Attention is calculated in parallel.
- The results from each head are concatenated into a single vector and passed through a final linear layer resulting in the final output.
Residual Network Block
is a block that uses shortcut connections, a.k.a. skip connections to allow a model to essentially skip a layer without making a discontinuity in the gradients during back propagation. The residual function result is the output of its own block layers plus the original input to the block.- x: input to a block of layers
- F(x): output of the block's layers
- H(x) = F(x) + x is the final output of the residual block
Weight Tying (sharing)
is the sharing of a matrix between different components of the model in order to reduce the number of free parameters that the model must learn.Linear Layer
in a neural network is a layer that multiplies the input by a weight matrix and adds a weight vector.Softmax Layer
is a layer that applies the softmax operator to the input, resulting in output components that are normalized.The Transformer
is a sequence-to-sequence model, and the original transformer is composed of the above components.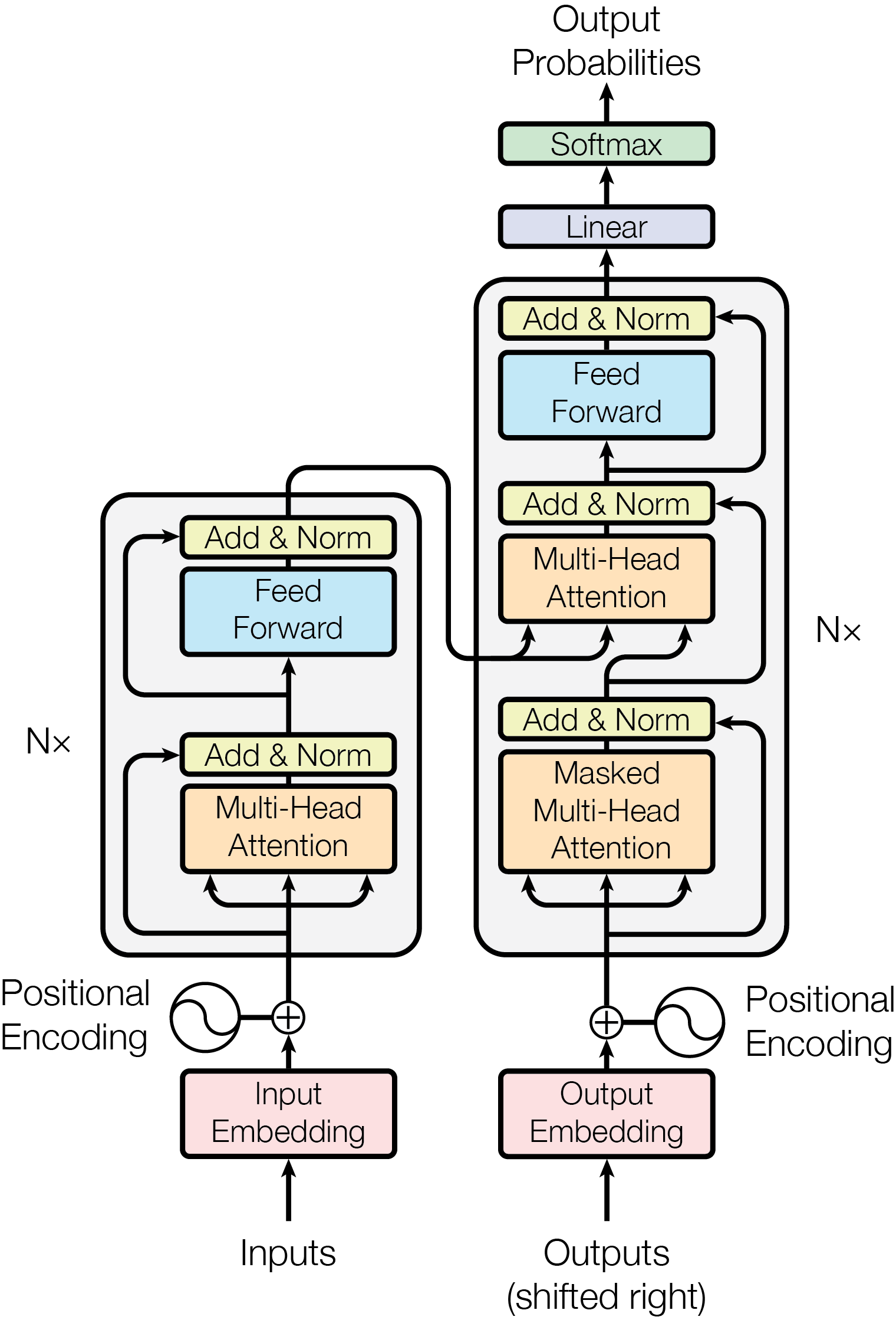 Figure 1 from
Vaswani et al. NIPS 2017)
shows that the canonicalized, tokenized inputs are
transformed into embeddings and assigned positional encodings.
The inputs are then put through an
encoder-decoder model.
Both the encoder and decoder are using stacks of blocks of
layers of multi-head attention, feed forward, and skip connection
blocks along with normalization between blocks.
Figure 1 from
Vaswani et al. NIPS 2017)
shows that the canonicalized, tokenized inputs are
transformed into embeddings and assigned positional encodings.
The inputs are then put through an
encoder-decoder model.
Both the encoder and decoder are using stacks of blocks of
layers of multi-head attention, feed forward, and skip connection
blocks along with normalization between blocks.
In the above figure, NX is N=6 identical layers in the encoder and N=6 identical layers in the decoder.
Encoder:
Each of the N=6 identical layers has a multi-head self-attention sub-layer followed by a simple position-wise fully connected feed-forward network sub-layer. Each sub-layer is in a residual block with output being LayerNorm(x + Sublayer(x)) where Sublayer(x) is the function implemented by that specific sub-layer and LayerNorm is a normalization function. The output dimension is the same size for all embedding layers and sub-layers.Decoder:
Each of the N=6 identical layers is a stack of the same 2 sub-layers of the encoder including the residual blocks and normalization, preceded by a sub-layer that is a masked multi-head attention over the encoder stack's output. Masking prevents the use of subsequent positions in the calculation. The output embeddings are all offset by 1 position from one another, so combined with masking, produce predictions for i that depend upon known inputs from positions less than i.The original transformer uses Multi-head Attention in the following ways:
-
in "encoder-decoder" attention layers:
☇ Every position in the decoder attends over all positions in input sequence. (mimics sequence-to-sequence models)- query (q): from decoder output from previous layer
- key (k): from the memory encoder output from current layer
- value (v): from the memory encoder output from current layer
- in encoder self-attention layers:
self-attention means query, keys and values are all from same place which is the output of the previous layer in the encoder.
☇ Each position in the encoder can attend to all positions in the previous layer of the encoder.- query (q): from memory encoder output from previous layer
- key (k): from memory encoder output from previous layer
- value (v): from memory encoder output from previous layer
- in decoder self-attention layers:
self-attention means query, keys and values are all from same place which is the output of the previous layer in the decoder. To preserve auto-regressive property, leftward information flow is prevented by masking out (set to − ∞) all values in the input of the softmax that are illegal connections.
☇ Each position in decoder attends to all positions in the decoder's previous layer.
Characteristics that Vaswanis et al improved with their Transformer architecture:
- reduced the total computational complexity per model layer
- increased the amount of computation that can be parallelized, as measured by the minimum number of sequential operations required
- increased the context length, that is, the path length between long-range dependencies in the network, measured by the maximum path lengths between any 2 input and output positions.
LLMs
[view/hide]
A list of modern LLMs.
There are variants of encoder, decoder and encoder-decoder architectures
of LLMs, but the most recent are based upon a decoder-only transformers
in Mixture of Experts architecture.
- in 2018, GPT-1 (Generative pre-trained transformer version 1)
was released by OpenAI as a decoder-only model.
Its capabilities were text generation, language translation,
creation of content, and question answering.
Innovations:- combining transformers
- unsupervised pre-training followed by supervised fine-tuning making training on large corpus of data and long context windows easier
- task-aware input transformations for textual entailment and question answering
- in 2018, BERT (Bidirectional Encoder Represenations from
Transformers) was released by Google as an encoder-only model.
Its capabilities were deeper understanding of context, useful
for example in question-answering, sentiment analysis, and
natural language inference, among others.
Innovations:- trained on a masked language model objective
- next sentence prediction loss
- in 2019, GPT-2
was released by OpenAI as a decoder-only transformer model.
Its capabilites were significant improvements in GPT-1 capabilities
including more human-like responses, longer context windows, and
better reasoning. It also was able to provide results on content
it was not trained on (no out-of-vocabulary errors, essentially).
Innovations:- 10-fold increase in parameter count (=1.5 billion) and size of training dataset compared to GPT-1
- in 2020, 2022, and 2023, GPT-3, GPT3.5, and GTP-4, respectively were released by OpenAI as decoder-only transformer models. Their capabilites were significant improvements over GPT-2 capabilities including better coherent results over longer context windows, less instruction needed, and better generalization across many NLP tasks. GPT-4 additionally had multi-modal image and text training allowing it to output text outputs from image inputs, and it was able to solve complex tasks in math, coding, vision, medicine, law, and psychology without specialized instruction.
- in 2021 LamDA was released by Google as a decoder-only transformer model capable of open-ended conversations.
- in 2021 Gopher was released by DeepMind as a decoder-only transformer model capable of text generation, language translation, creative content generation, and question answering. It had 280 billion parameters.
- in 2021 GLaM was released by Google as a
sparsely-activated mixture-of-experts model of
encoder-decoder transformer models.
It had 1.2 trillion parameters.
Innovations:.- In training it used 1⁄3 of the energy needed to train GPT-3.
- In inference it needed half og the FLOPs used by GPT-3 while achieving better performance.
- in 2022 Chinchilla was released by DeepMind as a decoder-only
transformer model.
Innovations:- added compute optimal scaling laws that focused on increasing the model parameter count along with scaling dataset size while conserving quality.
- in 2022 PaLM was released by Google as a decoder-only
transformer model.
Its capabilities were common sense reasoning,
arithmetic reasoning, joke explanation, code generation,
and translation.
It had 540 billion parameters.
Innovations:- ability to scale efficiently using the Google Pathways system
- in 2023 PaLM2 was released by Google as a decoder-only
transformer model.
Its capabilities improved upon PaLM and added
advanced reasoning tasks, including code generation using
a model with fewere parameters than PaLM.
- in 2023-now Gemini was released by Google as decoder-only
transformer models that use Mixture of Experts architecture.
Their capabilities include improvements in scalability, and inference
efficiency.
Gemini 2.5 Pro capabilities include reasoning
over complex problems in code, math, and STEM, as well as analyzing large datasets, codebases, and documents using long context window of up to
1 million tokens.
It supports structured outputs, function calling, search grounding,
thinking (see previous sentence), url context, caching,
code execution, and batch mode inference.
Innovations:- offers a family of models optimized for different sizes
- in 2024-now Gemma was released by Google DeepMind
as decoder-only
transformer models that are open source.
They're built upon the same research and technology used to create
the Gemini family of models.
Can accept text or image imputs. Capabilities include function
calling, complex analysis and generation tasks
and support for over 140 languages.
Innovations:- open-source models with high quality documentation, maintenance, updates, and support for small footprint models
- in 2023-now LLaMA was released by Meta AI
as decoder-only transformer models.
Its capabilities are advanced text and code generation,
complex reasoning and instruction following,
support for over 200 languages, and a broad knowledge base.
Innovations:- offers a family of models optimized for different sizes
- LLaMA context window of 4096 tokens improved its conversation abilities
- a focus on improving safety
- in 2023-2024 Mixtral was released by Mixtral AI as Mixture of Experts architecture composed from decoder-only transformer models. Its capabilities include math, code generation, multilingual tasks, instructions/
- in 2024-now O1 was released by Open AI
as mixture-of-experts models composed from
decoder-only transformer models.
Its capabilities are scientific reasoning tasks, math,
comprehension of physics, biology, and chemistry,
code generation.
Innovations:- complex reasoning abilities honed through reinforcement learning.
- in 2023-now Deepseek was released by DeepSeek
as mixture-of-experts models composed from
decoder-only transformer models.
Innovations:- Group Relative Policy Optimization (GRPO) training for Reinforcement-Learning (RL) uses a reward function that is a reponse normalized by the group's average response.
- multi-stage training process to address early model poor results: supervised fine-tuning, pure-RL, rejection sampling, followed by supervised fine-tuning and RL
LLMs in general handle tasks such as text classification, question answering, document summarization, and text generation (including language translation). Increasingly, more task specific LLMs are being made and task specific agents follow from that, and multi-agent systems of agents interacting with one another to accomplish tasks follow from that.
(2) LifeCycle
The first steps in building a Gen AI application are defining the goal of the project, finding a stable, robust source of data for it, and building the smallest working version to explore the feasibility of it. B.T.W. the contest requirement was to use generative AI as a uniquely valuable tool in an application which would otherwise be less capable of accomplishing its real world goals. For this I created a clinical trials assistant from multiple gen-AI agents.To create the protoype, I first hand picked published clinical trial articles which had complex medical terms. Using Google AI Studio for text summarization by the Gemini-2-*, Gemini-1-* and Gamma-3-* models gave very good results that did not require a medical background to understand. The prompts I used were simple and instructive zero-shot prompts. I used deterministice generative settings (temperature=0) with all agents. Neither model fine-tuning, nor parameter efficient tuning were deemed to be necessary for this prototype.
Standard software requirements, analysis, design and implementation were followed with additional elements added for generative AI architecture.
[view/hide]
Details of the gen AI lifecycle here
(also in
docs/lifecycle in the github repository)
- Requirements (functional and non-functional):
- Capstone capabilities: At least 3 of the get AI capstone capabilities must be included.
- Agents: text capable LLMs. All need to be able to reason, one needs to be able to perform document summarization, one (preferably a different model than the summarizer, needs to be able to evaluation the summarization, and one needs to be able to recognize valid disease names.
- Data: robust, stable API sources
- Deployment/Serving/Client:
- Cloud hosted LLMs supplied by Google.
- Stubs for cloud based logging.
- The code must run from start to finish within a Kaggle notebook. The assistant must be an interactive application, and so it needs to optionally run automatically too.
- Consideration for ease of porting to mobile environments is kept in mind.
- Prompts
- Zero-shot instructions for all tasks
- Logging, Monitoring:
- latencies for all API and LLM invocations
- size of data: number of input and output tokens
- drift of data: watching for APIs returning data different than expected
- errors
- user feedback
- Protect User from harmful content
- Ensure regulations for privacy and other guidelines are followed
- Latencies: Each response to the user should be less than 3 seconds ideally.
- QPS:
- Rate limiting for API requests. The requests are directly from the client Kaggle notebooks to the APIs. Rate limiting on client-side should be made. Model choices that handle scale well for the budget should be made.
- Analysis and Design
- Data I/O assessment
- data to and from the NIH APIs is small
- data to and from the Google LLM APIs is small
- Choice of LLMs w/ preference for smaller models, no need for image or audio in this prototype
- Gemini-1.5-flash and smaller models: SOTA, handles long context well, ability to follow complex instructions and complete complex tasks, document understanding, can take system instructions specifically, can output results in a structured format, can scale well, use is free up to rate and data limits, then increases.
- Gamma context window constraint of 128 k, ability to follow complex instructions and complete complex tasks. document understanding. it's an open source model that performs very well, though has fewer abilities than the Gemini models. The costs for rates and data sizes are free, but the model might have scale limits.
- Function Calling: client side methods to build and test
- query to user for disease name w/ option to exit
- Google LLM agent to validate the disease name
- retrieve clinical trials
- API request to clinicaltrials.gov, parsing, logging
- query to user for trial selection w/ option to exit
- query to user for citation selection w/ option to exit
- API request to NIHML's PubMed, parsing, logging
- article results summarization
- Google LLM agent to summarize text
- Google LLM agent to evaluate summarization
- parsing, logging
- Gen AI orchestration layer: langgraph
- Integrity of data: best practices are followed in using APIs. The APIs themselves and Kaggle follow secure practices.
- Integrity of logs: Kaggle environment is session based. cloud logging stubs are made but not implemented so no concerns there.
- Protection of User from Harmful content
- User Feedback is requested and logged. Additionally, the Kaggle notebooks have a messaging environment where users can ask questions or leave comments.
- Regulations: GDPR CCPA, and other guidelines are implicitly followed because no PII is requested nor stored.
- Prompts
- Versions: prompts are stored in language and version directories to allow mixing of components while experimenting with improvements for the application.
- Logging, Monitoring
- implemented in client locally w/ stubs for remote aggregation in the cloud
- Source version control in github
- Development tools were the Kaggle notebook and the JetBrains Pycharm IDE
- Implementation (see The Gen AI Application below)
The Gen AI Application
The application is hosted in a Kaggle notebook here. Langraph was used for orchestration of the function calls (a.k.a. tools) by client-side invocations (client-side rather than LLM invocations to reduce token use). A sequential planner pattern with conditional cycles was used for the workflow. Nodes were created for each function, and conditional edges from each node to the next in the sequence or to exit the application by user request.- node: user_input_disease
- next node: fetch_trials
- conditional edge
- node: fetch_trials
- next node: user_choose_trial_number
- conditional edge
- node: user_choose_trial_number
- next node: user_choose_citation_number
- conditional edge
- node: user_choose_citation_number
- next node: fetch_abstract
- conditional edge
- node: fetch_abstract
- next node: llm_summarization
- conditional edge
- node: llm_summarization
- conditional edge
- node: feedback_query
- next node: user_input_disease
- conditional edge
[to user]
"This librarian searches clinical trials for completed, published results and summarizes the results for you."
"Please enter a disease to search for (q to quit at any time):"
The disease name checker is an instance of ChatGoogleGenerativeAI with a chosen LLM and a deterministic temperature of 0. The disease name checker is given this prompt with the disease name and returns a response which includes meta data such as the number of input and output tokens:
[to LLM agent]
"You are a librarian at the National Institutes of Health.
Do you recognize the words {disease_name} as a valid disease name?
Answer yes or no."
The trials are retrieved from the US National Library of Medicine's Clinical Trials database and presented to the user.
The user selects a trial and published trial result citations are then presented to them. The user selects a result from the list and the summary of that result is retrieved from the US National Library of Medicine's PubMed database. A prompt with text summarization instructions is given to the document summary agent which has been configured for a deterministic response.
[to LLM agent]
"Summarize this text in simple terms in a serious tone."
The agent response is presented to the user. The agent response is asynchronously evaluated by another agent which is given a somewhat lengthy prompt of instructions. and the response evaluation is logged. The user is asked if they would like to submit feedback and if so, they are presented with a couple of questions with itemized choices. Their responses are logged. Lastly, the user is asked if they would like to make another query.
And that is the prototype. Thanks to Google for sponsoring this 5-day intensive course on Generative AI and providing great examples and resources for us to use!
References
- Gen AI Intensive Course Capstone 2025Q1, Howard et al. 2025, Kaggle
- Foundational Large Language Models and Text Generation (Barektain et al. 2025)
- Attention is All You Need (Vaswani et al. NIPS 2017)
- End-To-End Memory Network ( Sukhbaatar et al. NeurIPS 2015)
- Stanford CS 236 ( Videos, Notes)
- Introduction to Large Language Models
- LangGraph
- LangGraph Google GenAI